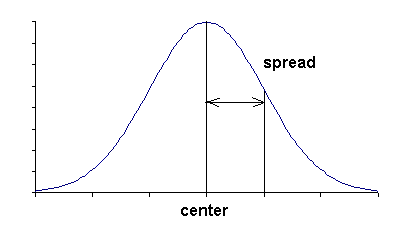
| (a) |
|
(b) |
|
(c) |
|
| (a) |
|
(b) |
|
(c) |
|
Ans for (a):
0.5 x 10 + 1.5 x 30 + 2.5 x 50 + 3.5 x 10 200
----------------------------------------- = --- = 2.0
10 + 30 + 50 + 10 100
Ans for (b):
0.5 x 30 + 1.5 x 50 + 3.0 x 20 150
------------------------------ = --- = 1.5
30 + 50 + 20 100
Ans for (c):
0.5 x 20 + 1.5 x 40 + 2.25 x 30 + 2.75 x 10 165
------------------------------------------- = --- = 1.65.
20 + 40 + 30 100